流式数据分析就像编织一张网,网住的是人生,网不住的是发际线。

面对下面这例20色的流式数据,我们总是犯同样的糊涂:抗体选择的逻辑关系是什么,设门逻辑是什么,如何准确找出目的细胞?………

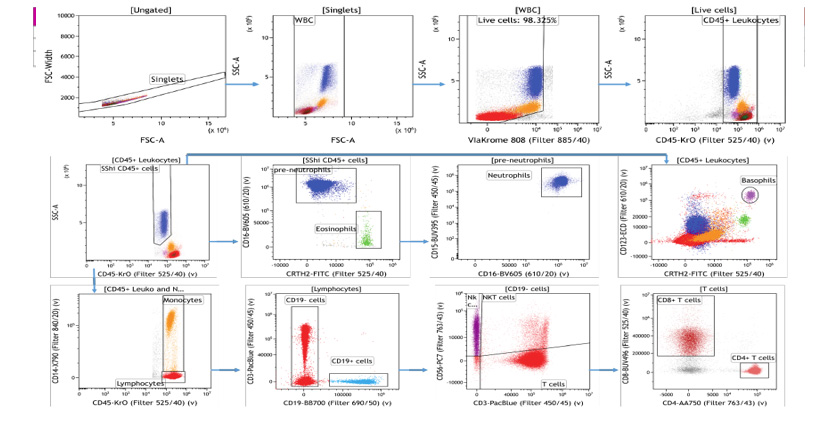
完成一例20色的方案:
-
基于丰厚的免疫学知识
-
基于丰富的流式分析经验,设门策略,分析思路
-
基于事实的预设性分析,容易遗漏有价值的信息
Kaluza联合Cytobank进行高维数据分析。

插件下载地址:https://www.mybeckman.cn/flow-cytometry/software/kaluza/downloads
插件安装:“Run as administrator”运行Kaluza软件”——→选择“插件管理” ——→安装“插件”

Cytobank AI算法快速解读流式数据
同样是20色的流式数据,将流式数据直接从Kaluza上传至Cytobank,根据需要完成降维和聚类分析。
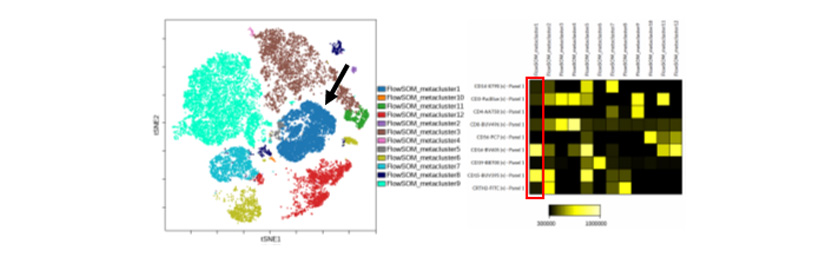
分析一:viSNE、FlowSOM和Heatmap呈现样本表型特点
FlowSOM自组织映射,根据表型标记物生成不同metacluster,该实验共分析12个metacluster。viSNE降维呈现不同metacluster。Heatmap分析metacluster的表现,同时得到相关细胞信息,例如metacluster 1(箭头和红框标识):CD15+CD16+。
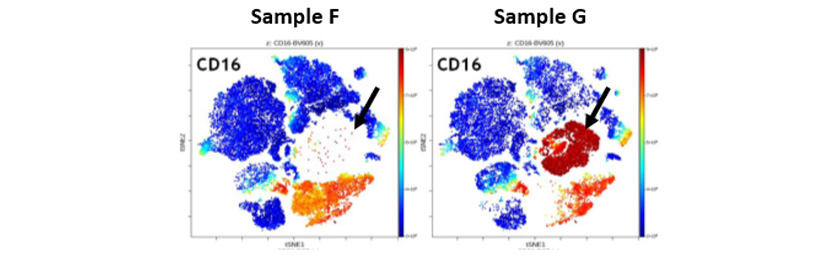
分析二:viSNE降维图呈现不同样本群体差异
不同metacluster借助viSNE,降维呈现在二维散点图。两组实验样本在viSNE图比较分析,直观发现样本F和样本G metacluster 1(箭头标识)含量存在较大差异。
分析三:SPADE比较分析样本群体差异
SPADE分析,使用Bubble鉴定不同细胞亚群,节点大小表示细胞数量,颜色表示对应表型标记物(本例CD16)的表达量。本例分析样本F和样本G在Neutro亚群(箭头标识)存在明显数量差异,样本F基本无该群细胞, Neutro亚群CD16强表达,与前述分析一致。

高维数据分析流程:
